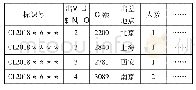
《表1 清洗后数据详情:传播视域下对京剧文化的认知分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
单位:条
数据采集完成后,存在大量不合格的数据,如字符编码错误、格式混乱、信息不完整、重复、空白、非文本等。直接利用未清洗数据进行分析可能会导致文本分词结果、关键词统计、情感分析出现较大误差,因此在数据处理前需要对数据进行清洗。清洗方法包括:(1)将微博中emoji表情通过python中的emoji包转换为文字进行储存;(2)通过正则匹配删除数据中多余的空格和不必要的符号(例如“/”“#”“*”等);(3)删除记录中不合规的数据,如重复数据、空白数据、主体信息为非文本(视频、图片)的数据;(4)删除微博中存在的官方博文。由于官方账号有较为明显的命名方式(如xx大学、xx京剧院、xx日报等),因此将电视台、广播、报纸、大学、京剧院、京剧团、报刊、杂志社、综艺平台作为关键词,将包括这些关键词的官方账号及其发布的博文进行剔除。数据清洗完成后得到符合条件的数据总数为35 865条,具体数量如表1所示。
| 图表编号 | XD00145431300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 侯文军、乐梦云 |
| 绘制单位 | 北京邮电大学数字媒体与设计艺术学院、北京邮电大学网络系统与网络文化北京市重点实验室、北京邮电大学数字媒体与设计艺术学院、北京邮电大学网络系统与网络文化北京市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}