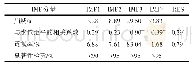
《表2 各IMF分量合并为新子序列的结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Elman神经网络的PM_(2.5)质量浓度区间预测》
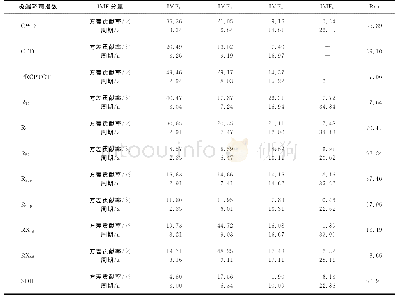
以北京市北京工业大学校园内监测点采集PM2.5质量浓度序列为例,对其进行统计学分析,如表1所示,可以看出偏度系数大于0,峰度系数大于3(正态分布峰度系数为3),说明该样本数据比正态分布更为陡峭,因此,PM2.5质量浓度序列具有高度非线性和不确定特性.为了有效解决该问题,对PM2.5质量浓度时间序列进行CEEMD,其结果如图4所示.由图4可知,IMF分量较多,若分别用Elman神经网络对每个IMF分量进行建模,则计算复杂度较高.因此,用样本熵来计算IMF分量复杂性程度,如图5所示;对IMF分量进行重组,如表2所示,最终所得到的重组结果如图6所示.在此基础之上,采用相空间重构方法选择最相关滞后值,提取最相关历史数据集,并对数据进行归一化至[-1,1],将前600组数据作为训练数据,后144组作为测试数据,从而实现对未来3 h大气中PM2.5质量浓度的预测.
| 图表编号 | XD00145302200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.10 |
| 作者 | 李晓理、梅建想、王康、李济瀚 |
| 绘制单位 | 北京工业大学信息学部、计算智能与智能系统北京市重点实验室、数字社区教育部工程研究中心、北京工业大学信息学部、北京工业大学信息学部、计算智能与智能系统北京市重点实验室、数字社区教育部工程研究中心、北京工业大学信息学部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}