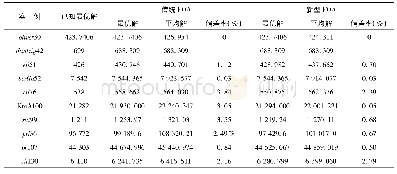
《表1 基于云模型FOA与标准FOA及文献改进FOA收敛精度对比 (popsize=100)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
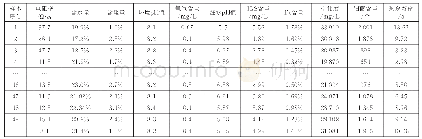
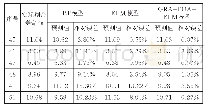
实验过程中设置算法的种群规模为100,最大迭代次数为200,设置搜索半径的最小值和最大值为22和5.设定一份试卷为一个果蝇个体,每份试卷的试题数量分别取30、50和70,经过20次独立运行的结果,如表1所示.采用正态云模型改进后的FOA果蝇个体在寻优过程中,味道浓度因子自适应调整搜索步长,对于味道浓度值大于平均味道浓度值的个体,,在寻优过程中被赋予最大搜索半径,加快了算法收敛速度;而对于味道浓度值小于平均味道浓度值的个体,在寻优过程中根据味道浓度因子被赋予自适应调整的搜索半径,提高了算法的收敛精度,因而在优化最小值Smin、平均值Smax、标准差Sst等表现出较好的效果.另外,在算法迭代过程中,以果蝇个体到原点的平均距离为期望生成云滴,使产生的可选解呈正态分布,促使算法可选解产生机制呈现出随机性和模糊性,提高算法的全局寻优能力.基于云模型的FOA算法在搜索初期,由于果蝇个体的味道浓度值赋予了较大的寻优半径,使得算法能够较快的收敛,而在搜索的后期根据味道浓度因子自适应调整步长,有效的避免了算法陷入局部最优,如图2所示.
| 图表编号 | XD0014042600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.12.01 |
| 作者 | 杜文军、孙斌 |
| 绘制单位 | 东北电力大学教务处、东北电力大学教务处 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}