《表5 不同天气类型下各模型预测误差分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
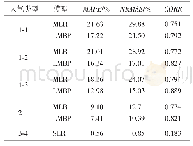
由于数据样本量较大,将kT≥0.5范围内的样本数据进行K-均值聚类验证[17-18],聚类数是3,对比交叉细分的方法,2种分类结果中样本的重复率大于80%,说明交叉细分方法有一定代表性且使用规则简便。根据图5,对于天气类型1-1、天气类型1-2、天气类型1-3,散射比与清晰度指数、能见度、总云量的相关性均较强,即此部分以这3种气象因子均一化数据作为输入,建立多变量线性回归模型(MLR)和LMBP神经网络模型[19-20];对于天气类型2,清晰度指数和总云量对散射比的影响力较大,即此部分以这2种气象因子均一化数据作为输入,建立多变量线性回归模型和LMBP神经网络模型;对于天气类型3-4,以总云量均一化数据为自变量建立一元线性回归模型(SLR),所有模型训练样本与预测样本随机分配,比例为8∶2,运算结果见表5。由表5可知,基于新的天气类型划分后,线性模型可降低预测误差,但较智能算法效果差。线性模型预测天气类型3-4最优,预测天气类型1-1最差,可能仍与天气类型中复杂的气象因子含量有关。综合对比后发现,天气类型1-1、天气类型1-2、天气类型1-3和天气类型2为选择LMBP神经网络模型为最优模型,天气类型3-4以总云量为输入,模型效果改善明显。
| 图表编号 | XD00139653700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.28 |
| 作者 | 李芬、刘迪、闫全全、陈正洪、程兴宏、赵晋斌 |
| 绘制单位 | 上海电力学院电气工程学院、上海电力学院电气工程学院、上海市电力公司检修公司、湖北省气象服务中心、中国气象科学研究院灾害天气国家重点实验室、上海电力学院电气工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}