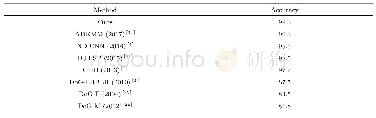
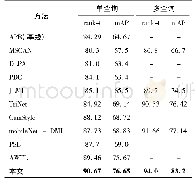
《表6 CK+数据集上与其他方法整体准确率对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
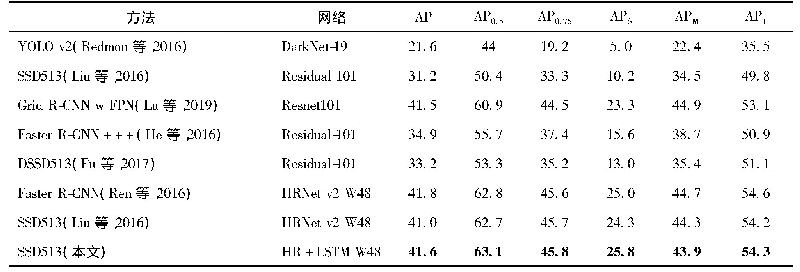
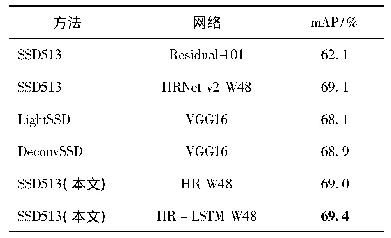
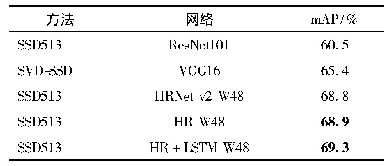
在CK+数据集的实验中发现,随着表情样本数量的减少,CNN-SIFT和CNN-SIFT-AVG的性能比CNN-ONLY模型的准确率和性能有所提高,且CNN-SIFT-AVG模型的性能相对更优。图12为CK+数据集在CNN-SIFT-AVG模型上实验的混淆矩阵。由图可看出,Angry、Fear、Sad会被轻微混淆,在识别中会导致错误,相比其他表情,Happy表情比其他表情更容易识别。但随着数据集的减少,SIFT的优势体现出明显的效果,相比FER2013数据库,在CK+数据库中,识别的准确率大幅度提高了。图13为CK+数据集下不同模型识别的准确率比较。表6为CK+数据集上与其他方法整体准确率的对比。
| 图表编号 | XD00134729400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 林克正、白婧轩、李昊天、李骜 |
| 绘制单位 | 哈尔滨理工大学计算机科学与技术学院、哈尔滨理工大学计算机科学与技术学院、哈尔滨理工大学计算机科学与技术学院、哈尔滨理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}