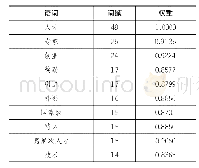
《表3 词频统计结果(前10)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文采用的文本分词方法是基于R软件,调用jiebaR安装包来实现。jiebaR包拥有自己的系统词典,且词汇量相当丰富,在此次文本分析中够用。在对文本分词之后,全文共分成了36905个词语,但其实这些词中包括了语气助词、副词、介词、连接词等,这些词语没有太大的分析意义,但出现的频率却很高,比如“得、呢、了、还、于是、那么”等。为了避免后期统计词频时增加许多的噪音,所以一般都会将这些词进行过滤处理。本文采用的是哈工大停用词,在筛出了停用词后剩余27277个词。经过分词和去停用词处理后,提取词频如表3所示。
| 图表编号 | XD00132357800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 陈俊宇、郑列 |
| 绘制单位 | 湖北工业大学理学院、湖北工业大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}