《表1 传统TF-IDF和改进后的TF-IDF方法在整个测试数据集上的分类性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文采用NLPIR2016(http:∥ictclas.nlpir.org/)对文本集进行分词和词性标注,剔除分词结果中对文档主旨没有任何提示作用的停用语,如“为何”、“与其”、“人们”等,以及一些数字和符号.由于一般而言,名词、动词和形容词是句子的重要组成成分,因此,为了抽取能够表征文档主要内容的词语,对于停用词过滤后的分词结果,本文只保留名词、动词和形容词3种词性的词语,去重之后将它们作为特征项.然后分别采用传统的TF-IDF方法和改进后的TF-IDF方法计算特征项的权重,结合KNN[15](K=8)和SVM[16]模型对数据集进行分类.分类器在整个测试数据集以及测试数据集各个类别上的分类性能分别如表1和表2所示.
| 图表编号 | XD00131317300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.20 |
| 作者 | 张琳、李朝辉 |
| 绘制单位 | 大连海事大学航运经济与管理学院、大连海事大学航运经济与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |

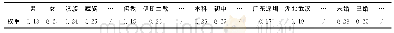




{kind=link}