《表4 货币对产出预测的网格搜索算法寻优结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《货币与信贷:谁更精确地预测了产出——基于机器学习算法的比较研究》
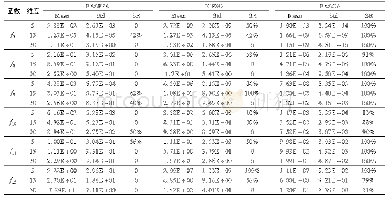
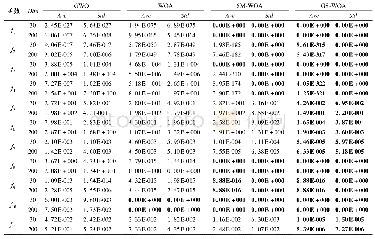
为避免网格搜索法在需要搜寻多个参数时排列组合数目过多,从而影响搜寻效率的问题,这里先按精确性要求将回归误差参数设定为ε=0.01,从而只对高斯核参数g和惩罚参数C进行算法寻优,并将二者的寻优搜索区间均设定为[-210,210]。具体地,在给定任意一组C、g和ε后,利用10折交叉验证的方法得到相应训练集各参数的平均预测均方误差,并对所得的不同情况下的结果加以对比,最终选择训练集平均预测均方误差最小的C、g和ε估计值,作为最优参数组合。不过,如果惩罚参数C很大,会导致因支持向量过多而产生的过度拟合(over fitting)问题(回归预测的泛化能力降低),所以如果各种情况下得到的平均预测均方误差相同或相近(相差在10-4以内),则优先选择惩罚参数C较小的参数组合。在具体的寻优过程中,本文采用了二次寻优的技术以提高参数寻优的精度,即先在大范围内进行粗略寻优以确定大致区域,再缩小搜寻范围以确定最优参数。表3表明,先通过粗略搜索确定参数C和g的大致区域为[2-6,2-3]和[23,26],再通过精细搜索确定参数C和g的值为0.035 9和64。网格搜索的过程及最优结果如图5、图6所示,类似地,产出的网格搜索寻优过程由图7、图8和表4给出。
| 图表编号 | XD0012691400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.06.05 |
| 作者 | 战明华、刘志媛、许月丽、田远 |
| 绘制单位 | 浙江理工大学经管学院 |
| 更多格式 | 高清、无水印(增值服务) |

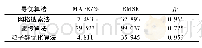


{kind=link}