《表4 两种方法测试结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
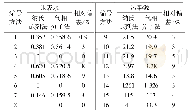
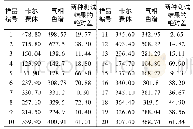
测试采用表2格式的仿真数据进行实验,对单机多线程方法与基于Spark Streaming的集群方法进行了仿真测试,令单机多线程方法运行在表3中的任一台从节点(Worker1或Worker2)虚拟机上,基于Spark Streaming的集群方法运行在表3中的3台虚拟机搭建的集群上,测试结果见表4,结果表明在相同的处理单元数量下,单机多线程处理方法的吞吐率为10.24 Mbps,基于Spark Streaming的集群方法为25.56Mbps,相比单机多线程方法的数据处理吞吐率提高了150%,并且基于Spark Streaming的集群方法可以通过增加从节点的方式进一步提升处理速率,具有很强的扩展能力,在实时参数解析处理中更具优势。
| 图表编号 | XD00122983700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.16 |
| 作者 | 张文彬、王春梅、王静、陈托、智佳 |
| 绘制单位 | 中国科学院国家空间科学中心、中国科学院大学计算机科学与技术学院、中国科学院国家空间科学中心、中国科学院国家空间科学中心、中国科学院国家空间科学中心、中国科学院国家空间科学中心 |
| 更多格式 | 高清、无水印(增值服务) |


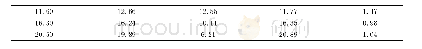
{kind=link}