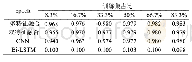
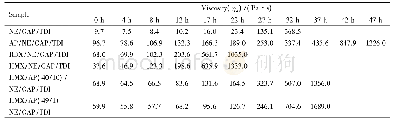
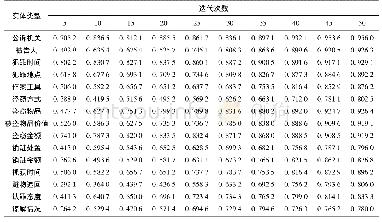
《表7 属性随加入训练样本量变化的权重排名》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由表7可以发现随机输入模型的样本数量达到全部(5/5)时,属性的权重排序和模型原输入样本得到的结果稍有差别,原因是由于在进行参数估计的时候使用了scikit-learn库中的Cross-validation模型。该模型对输入的有限数据集进行打乱,分为训练集和测试集,本文的实验设置测试集的比率是20%,由于算法自身随机抽取测试集的特点,每次选取的测试数据不同,导致最终结果稍有差异。如表7所示,起初属性的排名波动差异较大,然而随着样本的不断添加,模型性能逐渐保持一致,属性的级别排名逐渐稳定,模型鲁棒性得以检验。
| 图表编号 | XD00120612600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 孙悦、郭斌、欧阳逸、於志文、王柱 |
| 绘制单位 | 西北工业大学计算机学院、西北工业大学计算机学院、西北工业大学计算机学院、西北工业大学计算机学院、西北工业大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}