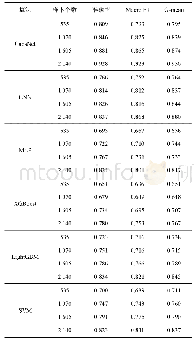
《表5 不同环境不同数据量下时空数据挖掘时间》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于HDFS+Spark的时空大数据存储与处理——以智慧无锡时空大数据为例》
从实验结果可以看出,随着数据量的增大,基于集群的Spark mllib分布式机器学习框架的并行计算效率明显占优势。当数据量增加到一定程度时,单机将无法胜任此工作。
| 图表编号 | XD00110616600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 贾旖旎、周新民、曹芳 |
| 绘制单位 | 无锡市自然资源和规划局、武大吉奥信息技术有限公司、武大吉奥信息技术有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}