《表2 UCI实验数据集误检率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
上述分析可得,在UCI数据集仿真实验中,本文算法在相同迭代次数下,相比传统Discrete-AdaBoost算法和Real-AdaBoost算法误检率更低,在二阶、三阶拟合情况下效果尤为明显。在算法训练的时间复杂度上,本文算法只需一次拟合即可得到弱分类器,而传统Discrete-Ada Boost算法在更新样本权重后每次都要遍历搜寻最佳阈值,随着样本增多,速度就会越慢,体现了本文算法在时间复杂度上的优势。
| 图表编号 | XD001101100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.20 |
| 作者 | 宋鹏峰、叶庆卫、陆志华、周宇 |
| 绘制单位 | 宁波大学信息科学与工程学院、宁波大学信息科学与工程学院、宁波大学信息科学与工程学院、宁波大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



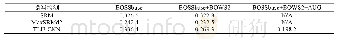

{kind=link}