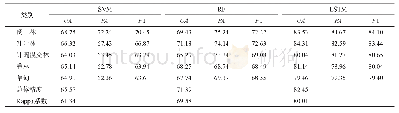
《表2 不同抽样比例RF、SVM方法分类精度比较Table 2Classification accuracy and Kappa coefficients of RF and SVM under di
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于随机森林模型的城市不透水面提取研究——以呼和浩特市为例》
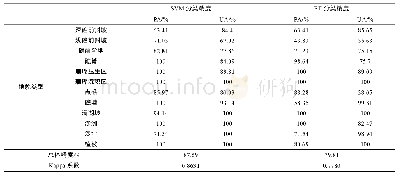
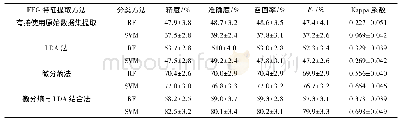
从测试集的总体精度和Kappa系数来看(表2),不论采用哪种抽样比例随机抽取的训练样本来构建模型,随机森林模型对于不透水面的提取总是优于支持向量机模型。相较于其他三种抽样比例,抽取70%的样本来提取不透水面,RF模型和SVM模型测试集的总体精度和Kappa系数都达到了最高。随机森林对于不透水面提取的总体精度达到了93.29%,比支持向量机的精度提高了2.03%。支持向量机的Kappa系数为0.8757,比随机森林的Kappa系数降低了0.0294。研究还发现较多的样本量并没有提高两方法对于城市不透水面提取的分类精度。当使用50%的样本来提取不透水面,两模型的总体精度和Kappa系数相差不大。说明当样本量较少时,使用RF模型来提取城市不透水面并没有表现更优,这恰好体现了SVM模型的优势。
| 图表编号 | XD001061100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.08.25 |
| 作者 | 郜燕芳、李俊明、刘东伟、任周鹏、王楠楠 |
| 绘制单位 | 内蒙古大学生态与环境学院、山西财经大学统计学院、内蒙古大学生态与环境学院、中国科学院地理科学与资源研究所、河南大学环境与规划学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}