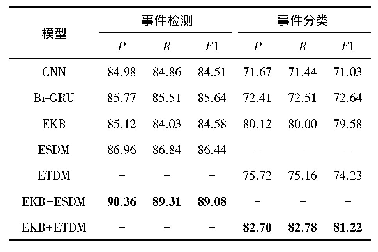
《表3 不同模型的中文事件检测效果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从表3可以看出,我们的ATT-BiLSTM模型在召回率和F值方面全都优于基于传统方法的Char-MEMM和Rich-L。Char-MEMM利用词语的上下文来提取词汇特征,并减少虚假论证;Rich-L使用联合模型,结合句子特征和语义特征来进行事件检测。这两种方法高度依赖于复杂的语言特征工程和自然语言处理工具。我们的ATT-BiLSTM模型是基于神经网络的方法,不需要人工设计复杂的特征,并引入BIO机制处理中文语言特定问题,可以有效避免从其他NLP工具传播的错误,如依赖关系解析和POS标记等。
| 图表编号 | XD0091819000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 沈兰奔、武志昊、纪宇泽、林友芳、万怀宇 |
| 绘制单位 | 北京交通大学计算机与信息技术学院、北京交通大学计算机与信息技术学院、北京交通大学计算机与信息技术学院、北京交通大学计算机与信息技术学院、北京交通大学计算机与信息技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}