《表1 日志样本:基于网络日志的用户行为刻画与预测研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
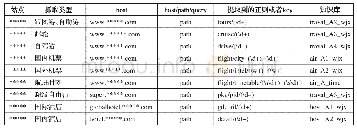
源日志主要来自于搜索引擎服务器或网络爬虫,将爬虫系统与各个站点连接,从而获取网络日志.目前常用的爬虫系统有百度统计、cnzz等.本研究采用搜狗实验室2008年6月部分网页查询需求及用户点击情况的网页查询日志.数据格式为:“用户查询词该URL在返回结果中的排名用户点击的顺序号用户点击的URL”.日志样本如表1所示.(本文选取个体用户查询信息多于8条的用户作为实验对象).
| 图表编号 | XD0088377300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.15 |
| 作者 | 康海燕、王紫豪、于爱民、谭雨轩 |
| 绘制单位 | 北京信息科技大学信息管理学院、北京信息科技大学信息管理学院、迈阿密大学计算机科学系、中国科学院信息工程研究所、北京信息科技大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}