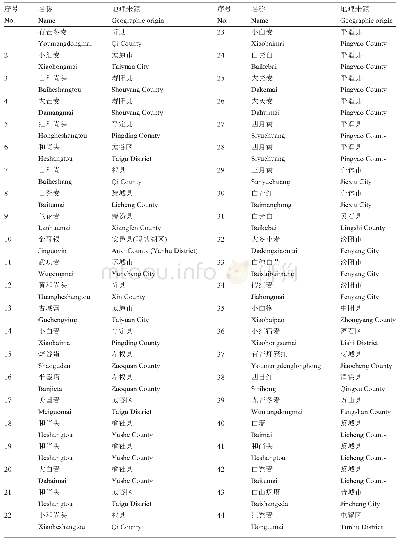
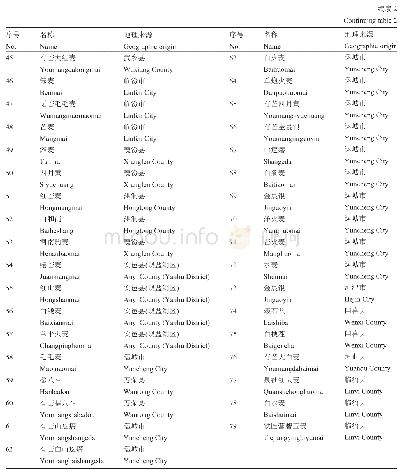
《表2 CERES-Maize模型在中国代表地区的品种遗传参数 (玉米)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:P1为幼苗生长特性参数(C·d);P2为光周期敏感参数(d);P5为灌浆期特性参数(C·d);G2为每株最大可能的籽粒数(粒);G3为最优条件下籽粒的灌浆速率(mg·粒-1·d-1);PHINT为出叶间隔特性参数(C·d)。表中参数结果来源于文献[11-19]。
模型评价一直以来都是作物生长模型发展的一个重要方面,是提高模型模拟精确度的关键环节,也是模型进入应用阶段的基础。理论上讲,模型模拟效果的好坏反映了系统模型对作物生长的环境、过程及过程间的相互作用的定量描述是否合理,能否较准确地刻画系统的行为特征,其评价指标需要与田间试验数据结合进行,应用较多的统计指标有均方根误差(RMSE)、均一化均方根误差(n RMSE)、模型性能指数(EF)、模拟值与测量值之间的一致性指数(d)等。具体实践过程中,要评价模型在当地是否适用,要与当地作物品种、自然环境条件、人为管理方式相结合,并通过多组田间观测数据对模型中的参数进行调试、更新和验证。根据大量的文献,近年来CERES-Maize模型在中国“本地化”的结果如表2所示[11-19],可以看出,针对不同区域、不同品种,各品种遗传参数的数值是明显不同的。这些参数可作为相近品种在具有相似地形、气候特征区域的初始值,具体使用时需要针对研究区域的气候特征、土壤特征、管理措施和作物品种,进行调试和验证,得到适宜的模型参数。完成对模型的“本地化”后,方能进行模型的应用。模型的评价与检验既为模型应用奠定基础,又通过不断提出新问题促进模型的发展。
| 图表编号 | XD0082723200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.20 |
| 作者 | 孙扬越、申双和 |
| 绘制单位 | 南京信息工程大学应用气象学院、南京信息工程大学气象灾害预警预报与评估协同创新中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}