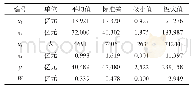
《表2 因变量与自变量的描述统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《阶层认同对青年农民工幸福感的影响分析——基于中国综合社会调查(CGSS)的数据实证》
本文主要研究阶层认同对青年农民工幸福感的影响,但因研究需要,我们还选取了相关变量纳入回归模型。(1)家庭经济状况。我们在“青年农民工”数据库中选择变量a64“您家的家庭经济状况在所在地属于哪一档?”,来表明其个人对其经济地位的认知。该变量选项为“1=远低于平均水平、2=低于平均水平、3=平均水平、4=高于平均水平、5=远高于平均水平”,测量等级为1~5,数值越高意味着家庭经济状况越好。(2)选取与经济地位有着重要关系的变量a65“您家拥有几处房产?”由被调查者据实填答,数值越大意味着房子越多;(3)选择表示“身体健康状况”的变量a15“您觉得您目前的身体健康状况是?”测量等级为1~5,数值越高意味着越健康。(4)选择表示“心理健康状况”的变量“a17在过去的四周中您感到心情抑郁或沮丧的频繁程度是?”测量等级为1~5,分数越高意味着心理健康状况越好;(5)重新编码“有无配偶”变量。选取变量a69“您目前的婚姻状况是”,将其中“初婚有配偶”“再婚有配偶”两类人视为有配偶的人群,剔除其他人群,将其重新编码为变量Ta69“有无配偶”,测量等级为“无配偶=0、有配偶=1”;(5)选择表示“和亲友联系的紧密度”的变量b5“您和亲人、朋友之间的接触和联系的情况怎么样?”测量等级为1~5,分值越高意味着联系越亲密。所有变量描述详见表2。
| 图表编号 | XD0078591400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.20 |
| 作者 | 张华 |
| 绘制单位 | 安徽大学社会与政治学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}