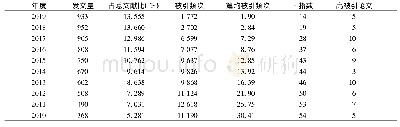
《表1 EMOBANK语料各领域文本数量的分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文使用EMOBANK语料库[4]来验证我们所提出的基于对抗式神经网络的多维度情绪回归方法.该语料库的数据源自两个公开语料库:SemEval07:task 14(http://nlp.cs.swarthmore.edu/semeval/tasks/task14/data.shtml)与MASC(http://www.anc.org/data/masc/corpus/)语料库,人工标注了共6个领域的英文文本的10 325条读者情绪和10 279条作者情绪,由多个标注者分别对文本的3个情绪维度:极性、强度、可控性进行读者情绪和作者情绪打分,分数区间为[1.0,5.0].EMOBANK中的读者情绪和作者情绪的文本数量并不相同,这说明语料库在标注时有少量文本未作读者情绪或作者情绪的标注.表1给出了EMOBANK包含的文本数量在各领域上的分布由于本文不涉及跨领域情绪回归的研究,而不同领域文本的相同情绪维度的特征分布存在一定的不同,因此本文仅在样本数最多的两个领域:新闻领域与小说领域上分别进行实验.
| 图表编号 | XD0073048700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 朱苏阳、李寿山、周国栋 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}