《表1 描述统计量:收入差距、医疗保险与健康贫困的实证研究——基于CFPS数据的证据》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《收入差距、医疗保险与健康贫困的实证研究——基于CFPS数据的证据》
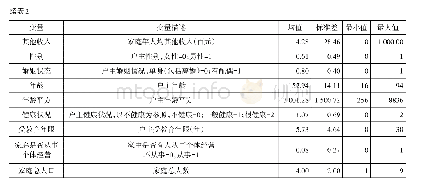
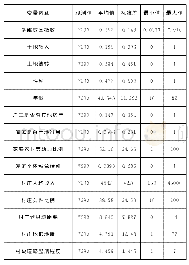
首先,在被解释变量方面,本文选取CFPS数据库的成人问卷中的自评健康,并将自评健康分为自评健康1(非常健康=5、很健康=4、比较健康=3、一般=2、不健康=1)和自评健康2(健康=1、不健康=0),其中自评健康2中的健康为CFPS数据库中的自评健康1变量中的非常健康、很健康和比较健康的合并,自评健康2中的不健康为自评健康1变量中的一般和不健康的合并。将自评健康作为衡量健康水平的被解释变量是该领域文献的常用做法,能够较好地代表个人的健康水平。其次,在解释变量方面,分为解释变量和控制变量。具体而言,第一,解释变量:本文研究中,将支出基尼系数(聚类到区县层面),作为衡量收入差距的代理变量的同时,为避免极端值的影响,对支出基尼系数(上下限各1%)进行了缩尾处理,其中,基尼系数的算法参照陈传波等学者的方法[20]。将新农合的参合情况这一虚拟变量(参加=1、否则=0)作为医疗保险的代理变量,以考察基于农民个体参合决策的收入差距对于健康水平的影响效应问题。第二,本文将可能影响我国农村居民个人健康水平的其他个人特征和经济因素,如年龄、性别(男=1,女=0)、婚否(婚姻存续=1,婚姻不存续=0)、受教育年限、是否有慢性病(有慢性病=1,没有慢性病=0)、人均家庭纯收入、医疗支出、家庭规模、做饭用水(使用自来水=1,未使用自来水=0)作为控制变量加入实证分析当中。具体描述统计量见表1:
| 图表编号 | XD0070094000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.15 |
| 作者 | 刘宇、聂荣 |
| 绘制单位 | 沈阳航空航天大学经济与管理学院、辽宁大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}