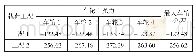
《表1 不同SSE工况下评分》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于LOF的K-means聚类方法及其在微震监测中的应用》
注:(1)~(3)分别对应SSE值从小到大排列的3种聚类方法。
为测试本文方法的优越性,选取传统K-means聚类和文献[14]K-means聚类算法作为对比。不同聚类方法的聚类效果可能受数据集的大小影响,本文选取数据集包含100,250,500,750和1 000个对象进行讨论。同一数据集分别运用上述3种聚类算法进行聚类计算,使用的聚类参数为x,y轴坐标,第k领域设为20。首先计算上述3种聚类方法在同一数据集、同一个分组数下的SSE值,SSE值由小至大分别记为(1),(2) 和(3),根据表1进行比较得到评分,见表1。例如:LOF-K-means聚类、传统K-means聚类和文献[14]K-means聚类算法的SSE值分别为100,200和150时,那么该SSE值由小至大排列后,对应表1中的评价工况4,且LOF-K-means聚类、传统K-means聚类和文献[14]K-means聚类算法评分分别为2,0和1。再将每1种聚类算法在2~10个聚类分组下得到的评分相加,得到总评分作为该聚类算法的综合SSE评价指标,其值越大则说明该聚类算法越好。为减少个别聚类结果对不同聚类方法的影响,将每种数量规模的数据集分别随机生成100次进行聚类计算,得到这3种聚类方法的综合SSE评分。图2为数据的聚类过程。可知初始聚类中心的选取与数据集的分布有关,且与数据集的局部密度紧密联系。
| 图表编号 | XD0069889500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.30 |
| 作者 | 刘德彪、李夕兵、李响、尚雪义 |
| 绘制单位 | 中南大学资源与安全工程学院、中南大学资源与安全工程学院、中南大学资源与安全工程学院、中南大学资源与安全工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



![表1 SSE治疗前后SRS-22量表中各项指标的评分比较[M(P25,P75)]](http://bookimg.mtoou.info/tubiao/gif/XHYX202001009_03400.gif)

{kind=link}