《表1 真实数据集细节:异常值自识别的低秩矩阵补全方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
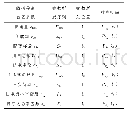
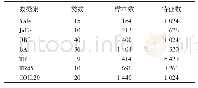
在本节中,将提出的算法SIOMC应用到具体的推荐系统问题中,分别基于公开数据集和本校在线平台成绩数据进行算法比较。公开数据集为广泛应用的推荐系统数据Jester数据集(http://www.ieor.berkeley.edu/~goldberg/jester-data/)和Movie数据集(https://grouplens.org/datasets/movielens/)。Jester数据集有73 496个用户对100个笑话开展的410万次评分,不同的数据集代表不同大小的数据规模;Movie数据集中是用户对自己看过电影的评分,三个数据集不同规模,用来比较实验中算法应用于不同大小数据规模的实验性能,数据集详情如表1所示。第一部分实验选用的两个数据集是人为对笑话或电影进行评分,整个评分矩阵是高度稀疏的,不能保证所有的评分都在正常范围内。例如在对电影的评分中,有的人可能对没看过的电影进行评分,因此数据集中存在部分异常值的情况。
| 图表编号 | XD0069558100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 李可欣、徐彬、高克宁 |
| 绘制单位 | 东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}