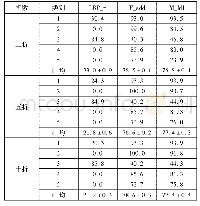
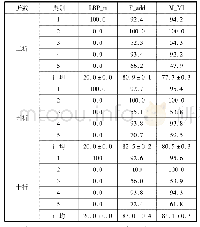
《表2 不同类别数的分类准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
此外,分别随机选取了5、10、15个类别设计实验。由表2可知,通过对不同类别数的文本进行分类,传统分类器和普通的CNN文本分类模型在类别数较少、低于10类的任务中,表现良好。但随着类别数不断增加,分类的准确率随之下降,主要是由于不同类别的文本在内容上存在交叉、重合等因素以及语料本身具有噪音信息。融合了LDA的卷积神经网络文本分类模型,有效地提取了文档的主题特征,并融合到卷积之后得到的文本信息之中,在传统卷积神经网络的基础上新增了主题信息,有助于文本分类准确率的进一步提高。同时,该模型在类别数较多的情况下也能表现良好,在20个类别的期刊论文分类任务中,平均准确率约比单一提取文本特征的卷积神经网络高出6%,由此可证明融合LDA的卷积神经网络的可行性和有效性。
| 图表编号 | XD0067426500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 汪岿、费晨杰、刘柏嵩 |
| 绘制单位 | 宁波大学信息科学与工程学院、宁波大学信息科学与工程学院、宁波大学信息科学与工程学院、宁波大学图书馆与信息中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}