《表7 各级地址模型性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
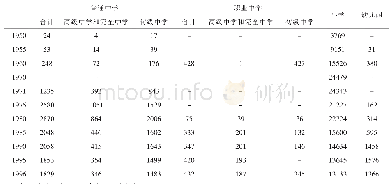
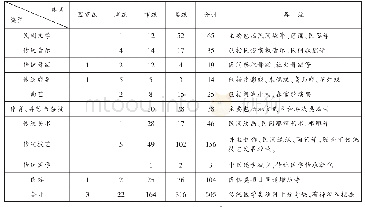
基于上述模型参数训练的4个中文地址分词模型在测试数据集上测试得到模型整体分词性能(表6)和各模型在各层级地址的分词性能(表7)。从表6可知,除LSTM模型3个指标和CRF模型召回率低于90%外,其余模型的相关指标均高于90%。LSTM、CRF、BiLSTM和BiLSTM-CRF这4个模型的指标值均依次递增。其中,BiLSTM-CRF模型的3个指标均最高,达到93%,模型整体分词性能最好,其次为BiLSTM模型,精确率高于91%,另外两个指标值也接近91%。LSTM模型的分词性能相对CRF模型和其他模型较差,3个指标值均低于90%。CRF模型召回率接近90%,精确率和F1值高于90%,一定程度上优于LSTM模型。另外,4个模型的召回率相对于精确率较低,原因可能是模型在训练数据上的效果比测试数据要好,模型存在轻微的过拟合,可以增加训练数据量或者修改Dropout率改善模型测试效果,提高召回率。LSTM模型的综合性能低于其他模型可能跟LSTM模型本身只能记忆过去信息,无法获取未来信息的特点有关,并且LSTM模型无法考虑输出标注间的关系,这种缺点可能导致模型输出存在标注不连续的错误。CRF模型的整体性能高于LSTM可能因为其能够设定大量的特征,在充分拟合数据分布的情况下仍能考虑模型输出标注间的限制。而BiLSTM为双向记忆,尽管没有限制输出标注间关系的能力,但通过记忆过去和未来地址信息的能力可以达到优于CRF模型的效果。最后,BiLSTM-CRF模型综合了上述模型的优点,既有强大的长期记忆能力,也能考虑输出标注间转移特征,因此各项指标均优于其他模型,具备更佳的地址分词效果。
| 图表编号 | XD0056580000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.25 |
| 作者 | 程博、李卫红、童昊昕 |
| 绘制单位 | 华南师范大学地理科学学院、华南师范大学地理科学学院、航天精一(广东)信息科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}