《表4 模型中的参数设置》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
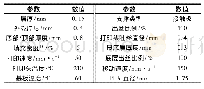
实验中,先使用CoreNLP(2)工具对问题文本和答案文本进行句子切分;再使用Jieba(3)工具来进行文本中文分词。使用深度学习框架Keras(4)进行LSTM网络和CNN网络的搭建。在使用基于LSTM网络与CNN网络的分类器时,词语特征用词向量来表示。具体而言,利用python的gensim(5)库对淘宝的问答文本进行词向量模型的生成,并使用该词向量进行所有神经网络模型的实验。考虑到实验性能等因素,词向量维度设为200。实验模型各参数如表4所示。
| 图表编号 | XD0054891600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 江明奇、沈忱林、李寿山 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}