《表2 描述性统计:高铁开通与分析师预测偏差——基于准自然实验研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
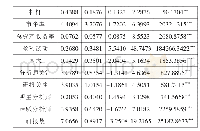
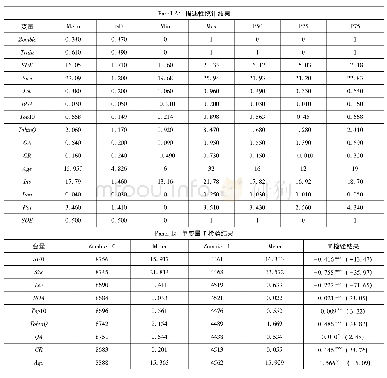
表2是对全变量的描述性统计分析结果。从表2中可以看出,Bias的均值为0.1816,意味着我国分析师的预测值与实际值的平均差距为0.1816。Treat变量的均值为0.2341,表明处理组样本数占全样本的23.41%,可见本文的处理组样本数量充足,可以展开研究。从控制变量的统计结果来看,Research的均值为1.5438,中位数为0,说明平均每个企业年调研次数为1.5438次,且超过半数以上的样本企业并没有开展调研活动。Attention的均值为9.2711,表示平均每个样本企业约被9个分析师团队关注。同时Attention的极大值和极小值之间相差48,说明各个企业之间的分析师关注度存在很大差异。此外,GDP的极小值为0.2843,极大值为30.7279,标准差为5.6938,可见各地区之间经济发展不均衡,存在较大差异。Distance的均值为0.1489,反映的是企业注册地所在城市距离中心城市的平均距离。
| 图表编号 | XD0053324000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.23 |
| 作者 | 姚圣、洪媛 |
| 绘制单位 | 中国矿业大学管理学院、中国矿业大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}