《表3 k取值优化表:基于拉曼光谱与k最近邻算法的酸奶鉴别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
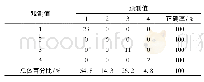
k最近邻算法是模式识别中经典的分类识别方法,核心思想是根据样本在特征空间中的k个最近邻样本中大多数属于某个类别,即判断该样本也属于该类别,因此,k是kNN关键参数之一[14]。同时,计算类别时,常常使用马氏距离或欧式距离,为此,比较了在固定判别模型其他参数的条件下,其他参数是主成分选取前40个,分解层数N=3,bior2.4小波基,不断改变k的取值,讨论了分别在马氏距离、欧式距离条件下,判别模型的5次平均识别率,结果如表3所示。依据表3可以看出,k=1时,平均识别率值最大,接近100%,随着k值的增加,平均识别率均有下降,说明在本实验体系条件下,k取值为1是最适宜的。比较马氏距离和欧式距离结果,平均识别率差异不明显,进一步结合已有文献报道认为,欧式距离是根据两点间对应坐标值之差的平方和再开方,而马氏距离是用协方差阵来把距离标准化后转化为无量纲的量来作为样本空间中两点的距离,判别结果更为合理,因此,本文最终优化选择使用马氏距离实现kNN判别[15]。
| 图表编号 | XD0050915800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.15 |
| 作者 | 张正勇、岳彤彤、马杰、孙树垒、刘军、王海燕 |
| 绘制单位 | 南京财经大学管理科学与工程学院、湖南大学化学生物传感与计量学国家重点实验室、南京财经大学管理科学与工程学院、南京财经大学管理科学与工程学院、南京财经大学管理科学与工程学院、南京财经大学管理科学与工程学院、浙江工商大学管理工程与电子商务学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}