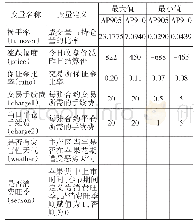
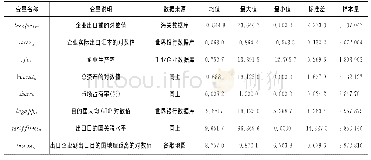
《表3 变量的定义、说明与描述性统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:与模型估计中样本量会因为变量的处理和Stata系统对样本的选择性剔除而发生变化不同,上表的统计均是针对549户农户和1417块地块整体进行的描述。
(3) 控制变量。控制变量包括农户特征、家庭特征、耕地特征、技术环境特征、村庄特征。农户特征变量选取了年龄、教育程度[6,10,37];家庭特征变量选取了家庭劳动力、家庭年收入、非农劳动力占比、非农收入占比、亲戚中是否有村干部[2];耕地特征变量选取了地块数、地块肥力、地块到家距离[13];技术环境特征变量选取了参加培训次数、信息渠道个数[2];村庄特征变量选取了村庄位置、村庄交通状况[38];本文也控制了县(区)的虚拟变量。需要注意的是,非农就业和农地流转是相互影响的[39,40],直接将非农劳动力占比和非农收入占比引入模型存在内生性问题,因此,借鉴田传浩等[41]、周来友等[42]的做法,选取村庄所有农户非农劳动力占比均值和非农收入占比均值作为上述两变量的工具变量(表3)。
| 图表编号 | XD0048809500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.25 |
| 作者 | 曹慧、赵凯 |
| 绘制单位 | 西北农林科技大学经济管理学院、西北农林科技大学应用经济学研究中心、西北农林科技大学经济管理学院、西北农林科技大学应用经济学研究中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}