《表4 Mozilla数据集中Accuracy@1的实验结果 (%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《DeepTriage:一种基于深度学习的软件缺陷自动分配方法》
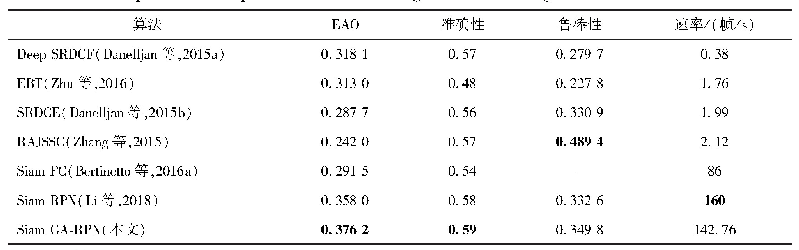
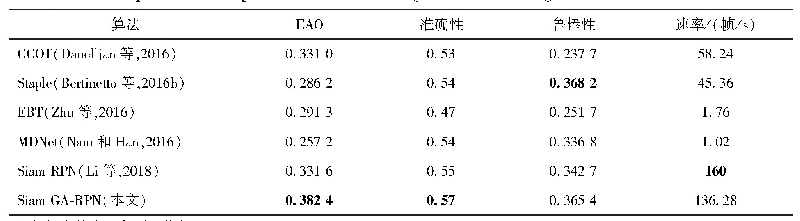
表2和表3显示的是本文所提方法和基准方法在Eclipse数据集上分别预测1名和5名开发者的结果.总的来说,本文提出的CNN模型要明显优于基准模型.在仅预测1名开发者的情况下,S_CNN的平均准确率比SVM的增加了15.69%,而M_CNN增加了22.96%.在预测5名开发者的情况下,与SVM相比,上述两种模型的平均准确率也分别增加了10.87%和17.48%.类似地,表4和表5显示了相关所有方法在M ozilla数据集上的预测效果.在预测1名和5名开发者的情况下,M_CNN的平均准确率比SVM的分别增加了16.01%和14.50%.这表明CNN在基于文本分类的软件缺陷自动分配问题上是有效的.
| 图表编号 | XD0045014300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 宋化志、马于涛 |
| 绘制单位 | 武汉大学计算机学院、武汉大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |


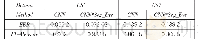

{kind=link}