《表2 测试数据中注视词的基线率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
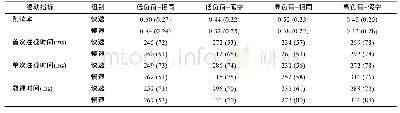
为了防止因训练数据量较少而可能带来的过拟合问题,本文采取了4种策略:1) 使用结构较简单的模型,即减少设计模型的复杂度,使模型深度仅为4层,单层的节点数最多处为50;2) 选用较少的特征,即仅选用词长和词性作为候选特征,在对实验精度影响有限的前提下,有效地防止了训练过拟合;3) 应用dropout丢掉一些网络节点,即丢掉10%的无用节点,以防止过拟合;4) 使用数据增强技术(data augmentation)扩充训练样本,即通过对文本序列数据应用一维卷积操作。卷积核长度(length)分别为2、3、4,权值依次取集合{unique(S)}中的元素,经过卷积运算之后训练样本增加的倍数为sizeof(unique (S)) ×3,实际的训练样本中所包含的单词数为:[sizeof(S)+lenth-1]×sizeof(unique (S)) ,lenth∈{2,3,4}。其中,unique表示去除重复操作,得到唯一单词,sizeof表示求元素个数操作。以数据集中的第一个受试为例,所阅读的单词数为2 743,sizeof(unique (S)) 数为1 272,采用长度为2、3、4的卷积核进行一维卷积操作之后,训练样本数据量扩充了3 816倍,实际的训练样本中所包含的单词数为18 854 856个(见表2)。
| 图表编号 | XD0039171800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 王晓明、赵歆波 |
| 绘制单位 | 西北工业大学计算机学院空天地海一体化大数据应用技术国家工程实验室、西北工业大学计算机学院空天地海一体化大数据应用技术国家工程实验室 |
| 更多格式 | 高清、无水印(增值服务) |




![表2 原棉短纤维率标样测试数据汇总[短纤维率(质量)]](http://bookimg.mtoou.info/tubiao/gif/ZHXJ202007016_25600.gif)
{kind=link}