《表3 部分主题词对应子时期资助文本数量/项》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
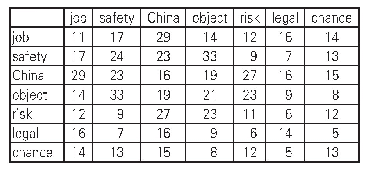
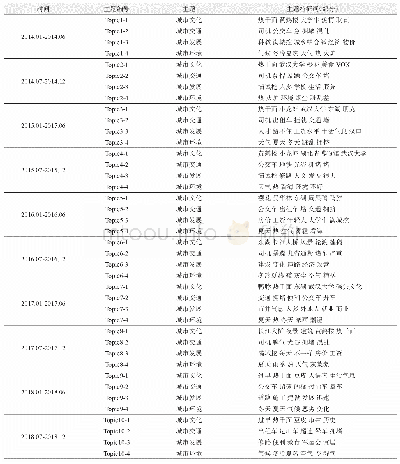
实验得到主题—主题词—项目序列号的混合分布聚态集群,采用非监督机器学习方式识别出项目文本中潜藏的主题信息。不同主题包含不同主题词和对应权重,每个项目文本数据都附加时间标签,利用PLDA模型主题分布集群可以得到主题与政府资助项目对应关系和结果,为后续新兴主题判别提供基础。表3展示的是各个子时期政府资助项目主题及其所对应的项目数量。在NSF数据集中每个项目都有唯一的项目号,建立多维度映射关系,可以找出每个政府资助项目所对应的主题及资助金额、资助起始时间及结束时间以及分布特点等项目文本基本特征,如表4所示,表示2015年政府资助项目相关文本特征要素及所对应的主题,该实验结果为后续新兴主题的探测提供奠定基础。
| 图表编号 | XD0036951400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.10 |
| 作者 | 徐路路、靳杨 |
| 绘制单位 | 南开大学商学院信息资源管理系、首都医科大学附属北京安贞医院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}