《表6 不同模型下句子压缩情况》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
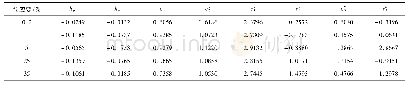
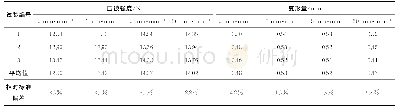
其中3LSTM模型表现较差,究其原因是该模型包含约100万个参数,使用当前训练数据集(36 000个句子对),不足以将参数调整至最优。而本文提出的模型参数较少,在强化文本语义建模基础上,能够高效捕捉数据分布规律,提取频繁出现特征,即关键语义、语法等信息,融合简单注意力机制,聚焦与当前词紧密相关的上下文影响信息,采用端到端的联合训练,自适应学习句子压缩决策因子,为输入文本中的每个单词分配一个有意义的权重,突出重要的动词和名词,而忽略常用的单词,如介词等,实现更精准压缩。
| 图表编号 | XD0035708700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.01 |
| 作者 | 鹿忠磊、刘文芬、周艳芳、胡学先、王彬宇 |
| 绘制单位 | 数学工程与先进计算国家重点实验室、桂林电子科技大学计算机与信息安全学院广西密码学与信息安全重点实验室、数学工程与先进计算国家重点实验室、数学工程与先进计算国家重点实验室、数学工程与先进计算国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
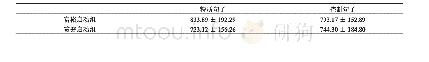



{kind=link}