《表1 GENIA V3.02语料库中实体标签分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《BioTrHMM:基于迁移学习的生物医学命名实体识别算法》
/%
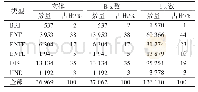
为了验证本文算法对生物医学命名实体识别的预测性能,选取传统的HMM算法与本文提出的基于迁移学习的Bio Tr HMM算法进行比较。目前,最常用的生物医学标注语料库是GENIA v3.02语料库,该语料库包含了来自MEDLINE的2 000个摘要标注文本(约360 000个单词),并且包含了36个词性类别,其中包含5个生物医学实体类型,本文使用了GE-NIA v3.02语料库(http://www.nactem.ac.uk/genia/genia-corpus)的数据进行实验。本文识别的是蛋白质命名实体,采用了精确率、召回率和F值[17]作为评价指标。GENIA v3.02语料库中实体标签分布说明如表1所示。
| 图表编号 | XD0035691100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 高冰涛、张阳、刘斌 |
| 绘制单位 | 西北农林科技大学信息工程学院、西北农林科技大学信息工程学院、西北农林科技大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}