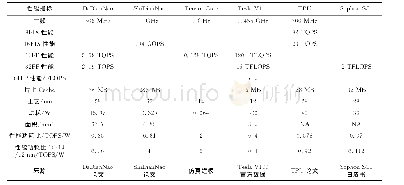
《Table 2 Detailed parameters of the deep learning IP core表2 深度学习IP核详细参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
700多个Tensor Core的组织和布局是非常复杂的,且如此细粒度的设计也并非本文所能涵盖和完成的,考虑到Tensor Core的结构是可扩展的,即可以将4*4*4的矩阵处理阵列扩展为8*8*8或16*16*16。若将Tensor Core矩阵处理阵列扩展为8*8*8,则Tensor Core的浮点性能为1TOPS,所需的Tensor Core个数为90个左右。将Tensor Core矩阵处理阵列扩展为16*16*16,则Tensor Core的浮点性能为8 TOPS,所需的Tensor Core个数约为12个。因此,本文最终选取矩阵处理粒度为16*16*16的Tensor Core作为本文中SoC系统设计的主要计算单元。由于SoC系统运行时不可能一直处于峰值性能,因此本文在进行系统设计时,需要适量地扩充计算单元个数,最终设计使用了16个Tensor Core。每4个Tensor Core为1组,形成1个Cluster,共有4个Cluster。
| 图表编号 | XD0035523700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 崔浩然、李涵、冯煜晶、吴萌、王超、陶冠良、张志敏 |
| 绘制单位 | 中国科学院计算技术研究所、中国科学院计算技术研究所、中国科学院计算技术研究所、中国科学院计算技术研究所、中国科学院计算技术研究所、中国科学院计算技术研究所、中国科学院计算技术研究所 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}