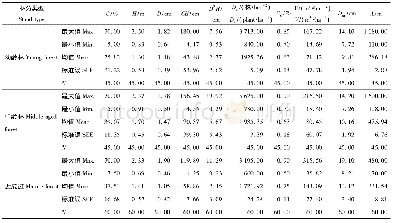
《表1 杉木人工林乔木层和下层灌木基本信息Tab.1 Basic information of Chinese fir plantation arbors and underlying shrubs》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:C为灌木盖度;H为灌木均高;D为灌木平均地径;Ds为林分密度;CS为郁闭度;V为林分蓄积量;Dm为平均胸径;A为海拔;N为样方数。Notes:C,shrub cover;H,average shrub height;D,average diameter for shrub;Ds,stand density;CS,canopy;V,forest stock volume,Dm,average bre
结合一般生物统计回归分析经常使用的回归方程,可选择多种线性和非线性的数学形式来进行预测模型的建立,其基本形式有:线性y=mx+b,对数y=lnx+b,多项式y=b+c1x+c2x2+…,幂函数y=cxb和指数函数y=cebx[30]。根据决定系数(R2)和标准误(SEE)及回归检验显著水平(P<0.1或P<0.05)等指标选取R2值高且标准误小的最优模型作为估测生物量的方程。本研究采用105个样本建模,45个样本检验,以总相对误差TRE(-5%~5%)、均方根误差RMSE(趋近于0)和平均预估误差MPE(<30%)作为模型的精度评价检验指标来进行检验[31]。在建模的过程中,为避免各自变量之间存在严重的多重共线性问题,即同时存在于同一方程中会导致参数估计值的方差增大,采用方差膨胀因子(VIF)检验各变量之间的多重共线性,当VIF>2时则认为共线性严重,去除共线性严重的变量。
| 图表编号 | XD003003000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.03.01 |
| 作者 | 耿丹、夏朝宗、张国斌、刘晓东、康峰峰 |
| 绘制单位 | 北京林业大学森林资源生态系统过程北京市重点实验室、国家林业局调查规划设计院、国家林业局调查规划设计院、北京林业大学森林资源生态系统过程北京市重点实验室、北京林业大学森林资源生态系统过程北京市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}