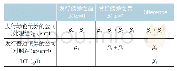
《表2 DID模型中各参数含义》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
双重差分法对处理组与对照组在做市商制度实施前后的指标进行两次差分,可以有效消除个体本身存在的差异及与政策影响无关的时间效应导致的偏差,克服内生性问题。为了避免对照组的选择性偏差,本文采用倾向得分匹配方法(PSM),基于可观测变量,逐个选取与处理组公司特征相近的对照组公司。PSM使用LOGIT回归模型综合样本多个特征值得出倾向得分值(Propensity Score,简称PS值),根据处理组的倾向得分值,选择与处理组各公司倾向得分值最接近的公司作为处理组的配对样本,即对照组,从而实现多元匹配。PSM匹配变量是公司总股本(SIZE)、营业收入增长率(GROWTH)、所有权结构(OWN)、净资产收益率(ROE)、资产结构(LEV)和股价水平(LNPRICE)。经过做市时间与日交易行情筛选,处理组有69家公司,运用PSM匹配方法在剔除处理组的4501家样本公司中逐一寻找与处理组特征最为相似的69家配对公司,再对“处理组—对照组”运用DID模型进行回归分析。基于DID的模型如下,模型各参数含义见表2。
| 图表编号 | XD0029097100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.23 |
| 作者 | 姚禄仕、李敏 |
| 绘制单位 | 合肥工业大学管理学院、合肥工业大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}