《表3 参数优化结果:基于SMOTE的XGBoost算法在风机叶片结冰预测中的应用》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于SMOTE的XGBoost算法在风机叶片结冰预测中的应用》
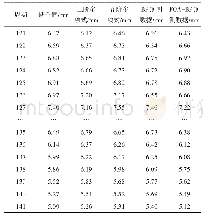
实验得知n_extimators与learnin_rate在调参时相互依赖,且参数booster在非线性数据集上只有gbtree,dart两种选择,故对这三个参数进行网格搜索调参(GridSearch)。对其余需要调参的六个参数依次使用学习曲线调参。用学习曲线选择最优参数时,需要选择合适的模型评估指标。精确率是常用于分类模型的评估指标,衡量模型正确分类样本占总样本的比例。由于风叶结冰数据占总数据集比例较少,即使模型将所有样本判定为正样本也有较高的精确度,但此时模型效果欠佳,因此需要选择更加合理的模型评估指标,在保证模型精确率的同时保证结冰数据的召回率。F1 Score,又称为平衡F分数(Balance F Score),被定义为准确率(accuracy)和召回率(recall)的平均分数,公式为:,综合考虑了召回率(recall)和特异度(specificity),广泛应用于不平衡数据集分类器的评估。两种评估指标取值范围均为(0,1],越接近1说明模型表现越好。图6为max_depth参数的学习曲线图,由图可知,当参数取值为2、4、6、8、12时,模型处于模型过于简单的欠拟合状态;取值为12、14时,G-mean和F1 Score都处于峰值,此时模型分类效果最好;当取值为16、18、20时,XGBoost树模型过于复杂,拟合情况一般,当取值14时,模型具有较高的分类表现和泛化能力。其他参数的优化过程与之类似,在此不进行赘述,参数优化最终结果如表3所示。
| 图表编号 | XD002447200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.25 |
| 作者 | 邸瑞、陈正鸣、吕嘉 |
| 绘制单位 | 河海大学物联网工程学院、河海大学物联网工程学院、河海大学物联网工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}