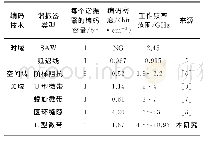
《表1 部分词性标准对照表Tab.1 Parts of pos tags》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《结合词性信息的基于注意力机制的双向LSTM的中文文本分类》
首先,本文利用无监督学习方式的分布式表示模型,将每个词语和词性标签映射到向量空间中,用以生成能够表示词语语义和词性自身含义的向量表示。首先采用分词工具对中文文本进行分词和词性标注以获取词语序列w={w1,w2,…,wn}和对应的词性序列wp={wp1,wp2,…,wpn},其中n表示文本长度,w1表示在词语序列中的第1个词语,wp1表示w1对应的词性;然后通过使用分布式表示模型生成基于词向量的上下文表示vw={vw1,vw2,…,vwn}和基于词性向量的上下文表示vp={vp1,vp2,…,vpn},其中vw1,vp1∈Rd分别表示词语w1和词性wp1的向量表示,d表示向量维度的大小,部分词性标注对照表如表1所示。
| 图表编号 | XD0024260100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.10.01 |
| 作者 | 高成亮、徐华、高凯 |
| 绘制单位 | 河北科技大学信息科学与工程学院、清华大学计算机系、河北科技大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}