《表1 数据集特征:基于交点的新层次聚类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证新的层次聚类算法,将其应用于三个数据集[17],数据集的详细信息如表1所示。所有提到的数据集都有预定义的标签,在不使用其类标签的情况下使用它们来形成聚类。将分层、分区、基于密度、基于网络和基于模型的层次聚类用于数据聚类,并将其结果与新聚类算法的结果进行比较。如前所述,在这些实验中,所有数据集都预定义了标签,因此可以使用它们来计算聚类算法的纯度,并根据其准确性对结果进行排名。聚类方法的准确性如图5所示,毫无疑问,聚类结果总是需要最低的聚类间距和最高的聚类相似度。换句话说,每个聚类的成员应尽可能地彼此靠近,这被定义为紧密度,而方差是紧密度的常用度量,因此,本文还计算了数据集的每个聚类中的属性值之间的方差。通过比较每个聚类的方差值,可以测量每个聚类算法如何在一个聚类中设置相似的数据点。除了纯度之外,方差分析还可以帮助评估聚类的准确性。肝病数据集、甲状腺病数据集和糖尿病数据集的方差值如图6~图8所示。
| 图表编号 | XD00226776300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.10 |
| 作者 | 李青旭、陈天鹰、胡波 |
| 绘制单位 | 华北计算机系统工程研究所、华北计算机系统工程研究所、华北计算机系统工程研究所 |
| 更多格式 | 高清、无水印(增值服务) |
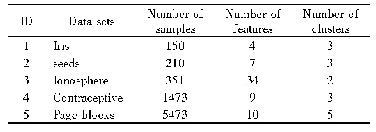





{kind=link}