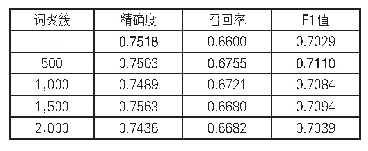
《表2 CRF模型在不同特征设置条件下的性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
将标注文献按照10折交叉验证的方式随机分为训练集和测试集,采用一般语义特征、字符特征、大小写特征、词聚簇特征来对数据进行刻画[4],与CRF模型对比,考察Bi LSTM-CRF模型的合理性、科学性和优越性。利用CRF++,选用Unigram模板,在构造词聚簇特征时,选择500、1,000、1,500、2,000簇进行布朗(Brown)聚类[34],得到4种不同簇的特征表示。还考虑不加入词聚簇特征的情形,由此共有5种特征设置。从表2看出,加入词聚簇特征的CRF模型均优于未加入词聚簇特征的CRF模型。当聚类的簇数为500时,CRF模型的召回率、F1值效果最好,故本文将词聚簇数目设置为500。
| 图表编号 | XD00211522000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.10 |
| 作者 | 安欣、徐硕、叶书路、柳力元 |
| 绘制单位 | 北京林业大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}