《表4 最不利计算工况:基于识别率的多叉树森林k-匿名算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
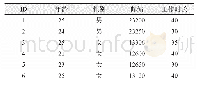
使用UCI机器学习数据集中的Adult数据进行算法验证,共32 561条数据,包括18种属性。由于k-匿名只对准标识符进行处理,因此选择Age、Workclass、Education、Marital-status、Gender、Nativecountry、Race等7种属性作为准标识符属性集,如表4所示。对数据进行预处理,删除带有缺失数据的元组。经过处理后保留30 169条。实验环境如表5所示。
| 图表编号 | XD00211262600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 陈先来、罗霄、刘莉、李忠民、安莹 |
| 绘制单位 | 中南大学大数据研究院、中南大学医疗大数据应用技术国家工程实验室、中南大学生命科学学院、中南大学生命科学学院、中南大学生命科学学院、中南大学大数据研究院、中南大学医疗大数据应用技术国家工程实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}