《表2 取值标度表:基于识别率的多叉树森林k-匿名算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
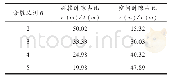
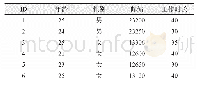
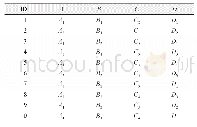
一般来说,要发布的数据可能涉及两种与隐私保护相关的数据:第一种是敏感属性,如疾病诊断信息、收入等敏感信息;第二种是准标识符(QID)属性集,即能够通过链接的手段识别出个体的各种属性组合成的元组[20],如{age,gender,race,country}。当每种组合仅有一个元组时,准标识符可以通过链接攻击定位到具体的个体。当每种组合存在多个元组时,这些元组构成等价类。因此,需要在数据发布时考虑k-匿名原则:保证每个QID至少有其他k-1个相同的值。即数据集中准标识符等价类的数量至少为k个。k-匿名的实质是利用原数据生成一个满足k-匿名要求并保留有效信息的表。表1和表2分别为原始数据表和经过泛化后满足k-匿名要求的匿名数据表(k=2)。
| 图表编号 | XD00211261900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 陈先来、罗霄、刘莉、李忠民、安莹 |
| 绘制单位 | 中南大学大数据研究院、中南大学医疗大数据应用技术国家工程实验室、中南大学生命科学学院、中南大学生命科学学院、中南大学生命科学学院、中南大学大数据研究院、中南大学医疗大数据应用技术国家工程实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}