《表2 优选后的注采井组数据》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于多变量时间序列及向量自回归机器学习模型的水驱油藏产量预测方法》
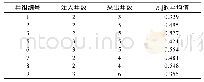
机器学习模型的适应性主要取决于数据的数量和质量两个方面。表5给出了8个井组所有采出井累计产量预测结果,可以发现3、6、8号井组的相对误差较小,1、9号井组的相对误差较大,结合表1中数据量分析可以发现,数据量的多少对VAR模型的拟合预测精度影响并不显著;相比而言,数据的质量是保证VAR模型可靠性和可用性的关键,结合表2中|Rij|的平均值分析发现,总体而言|Rij|的平均值越大,井组的机器学习模型预测精度越高,说明该参数可以用来评价不同井组机器学习模型的适应性。同时对比1、9号井组|Rij|的平均值发现,虽然9号井组|Rij|的平均值要比1号井组大,但9号井组的相对误差较大,同时从表2中发现,9号井组的注采井数明显多于1号井组,说明注采井数也会对井组累计产量预测结果产生一定影响。对比表5中机器学习和历史拟合结果可以发现,机器学习模型预测结果整体相对误差比历史拟合要小,说明VAR模型对井组累计产量的预测效果更好。
| 图表编号 | XD00208741100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.23 |
| 作者 | 张瑞、贾虎 |
| 绘制单位 | “油气藏地质及开发工程”国家重点实验室西南石油大学、“油气藏地质及开发工程”国家重点实验室西南石油大学 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}