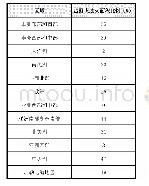
《表1 全球森林土壤呼吸数据集的数据结构示意》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对全球土壤呼吸数据集进行观察分析可得,数据集依据公开研究所涉及的全指标进行了可视化数据维度的构建,相关维度下数据量相对较小;数据来源国家(Country)、数据来源地区(Region)、气候带(Biome)、生态系统类型(Ecosystem_type)、年平均气温(MAT)、年平均降水量(MAP)、测量方法(Meas_method)、土壤呼吸的年通量(Rs_annual)维度下,数据充分对应,数据量较丰富,能够有效开展环境因子影响及空间差异的具体分析;数据集包含森林土壤呼吸、草原土壤呼吸、农田土壤呼吸、湿地土壤呼吸等;质量标志为Q01、Q02、Q03、无标志的数据可信度较高,有利于开展分析,得出可靠结论。基于上述观察分析结论,综合本文研究要求,确定如下原则进行数据清洗、加工,构建全球森林土壤呼吸数据集,数据清洗、加工原则包括:以数据来源国家(Country)、数据来源地区(Region)、气候带(Biome)、生态系统类型(Ecosystem_type)、年平均气温(MAT)、年平均降水量(MAP)、测量方法(Meas_method)、土壤呼吸的年通量(Rs_annual)为关键词抓取对应数据;以生态系统类型为清洗、加工维度,筛选抓取生态系统为“Forest”的对应数据;抓取质量标志为Q01、Q02、Q03、无标志的对应数据。
| 图表编号 | XD00206444400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.28 |
| 作者 | 施展 |
| 绘制单位 | 浙江农林大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}