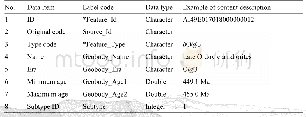
《Table 1 Part-of-speech tagging of named entity in ANSJ》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《Hierarchical clustering based on single-pass for breaking topic detection and tracking》
For each report,named-entity vector space model(NE-VSM)is applied.The weight of feature vector is calculated by named-entity identified term frequencyinverse document frequency(ITF-IDF),which is an improved version of basic TF-IDF.Named entities are identified by several POS tags shown in Table 1.
| 图表编号 | XD0020606300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.12.01 |
| 作者 | 李风环、Zhao Zongfei、Wang Zhenyu |
| 绘制单位 | School of Computers,Guangdong University of Technology、School of Software Engineering,South China University of Technology、School of Software Engineering,South China University of Technology |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}