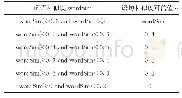
《表1 0 两种调优法在词语相似度任务上的比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
这些数据集中,每个问题都包含一个词对以及它们的一个相似性得分。相似性得分由若干标注者对该词对的相关性进行打分,分值介于0~10(分值越高表示该词对更相关或更相似)。利用词向量表示计算词对的夹角余弦,将该值作为数据集中词对相关性的度量值,使用Spearman相关系数作为计算结果与标注结果相关程度的指标,结果如表10所示。
| 图表编号 | XD00202130400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.05 |
| 作者 | 牛倩、曹学飞、王瑞波、李济洪 |
| 绘制单位 | 山西大学软件学院、山西大学软件学院、山西大学软件学院、山西大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}