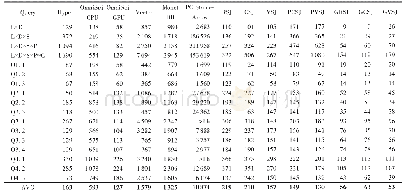
《表4 星形连接性能:面向多核CPU和GPU平台的数据库星形连接优化》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:L为lineorder表,D为date表,S为supplier表,P为part表,C为customer表;其中LD代表lineorder与date表连接,其他的以此类推;Q1.1等是SSB的对应查询时间;AVG是SSB查询的平均运行时间;RSJ为CPU行连接,CSJ为CPU列连接,VSJ为CPU向量连接,PCSJ为CPU压缩列连接,PVSJ为CP
表4最后一行显示了不同数据库及算法在SSB连接测试中的平均查询执行时间。SSJB测试结果显示,GPU端算法性能显著优于CPU端算法性能,Omni Sci GPU星形连接性能也显著优于其他数据库。CPU端算法中基于压缩向量的算法PCSJ性能较好,低选择率带来较高的压缩处理性能收益。GPU端算法中SJ执行时间略长于行式处理算法GRSJ和向量处理算法GVSJ,优化连接中间结果在GPU端同样获得性能收益,但GPU端算法之间的性能差异较CPU端小。数据库方面,基于实时编译技术的Hyper性能优于基于CPU端数据库,基于向量处理技术的Omni Sci CPU和Vector也优于基于列处理技术的Monet DB。
| 图表编号 | XD00201803500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.10 |
| 作者 | 刘专、韩瑞琛、张延松、陈跃国、张宇 |
| 绘制单位 | 数据工程与知识工程教育部重点实验室(中国人民大学)、中国人民大学信息学院、数据工程与知识工程教育部重点实验室(中国人民大学)、中国人民大学信息学院、数据工程与知识工程教育部重点实验室(中国人民大学)、中国人民大学信息学院、中国人民大学中国调查与数据中心、数据工程与知识工程教育部重点实验室(中国人民大学)、中国人民大学信息学院、中国气象局国家卫星气象中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}