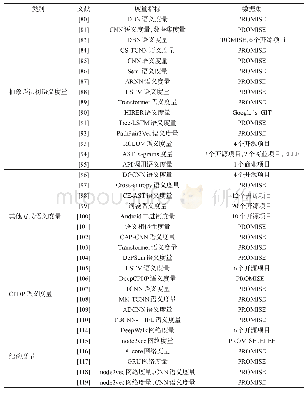
《表3 研究文献中度量指标和数据集(一)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
传统代码度量主要关注程序的统计特征,并假定有缺陷的软件模块和无缺陷的模块具有可区分的统计特征和面向对象特征。但是,研究者[80]通过对实际开发的软件模块观察发现,现有的传统代码度量指标无法区分不同语义的模块,即具有不同语义软件模块可能具有相似或相同的传统代码度量指标。例如,在图2中,有两个Java文件,两个文件都包含一个for语句和两个函数调用。使用传统度量来表示这两个代码段时,它们的特征向量是相同的,但是,语义信息明显不同。如果队列为空,调用remove()时,File2.java将遇到异常,需要建立更准确的预测模型来区分此类语义差异的模块。为了捕获源代码中的复杂语义信息和语法结构,Wang等人[80]首次提出利用深度学习从源代码中提取语义特征。
| 图表编号 | XD00201566800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.01 |
| 作者 | 杨丰玉、黄雅璇、周世健、郑巍 |
| 绘制单位 | 南昌航空大学软件学院、南昌航空大学软件测评中心、南昌航空大学软件学院、南昌航空大学软件测评中心、南昌航空大学软件学院、南昌航空大学软件学院、南昌航空大学软件测评中心 |
| 更多格式 | 高清、无水印(增值服务) |

![表3 本文方法与文献[1,14,15]方法在筛选数据集上的评价指标对比](http://bookimg.mtoou.info/tubiao/gif/JSJY202008034_08200.gif)

{kind=link}