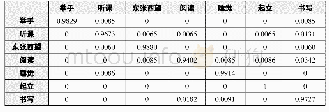
《表1 日常行为识别方法小结》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
如前所述,智慧家居中居民日常行为识别方法可以分为数据驱动的方法和知识驱动的方法。如表1所示,知识驱动的方法的优势在于识别模型的可移植性较强,且无需对数据进行标注。其局限性在于居民日常行为表现的多样性,导致构建、维护一个完备的识别模型较为困难,而且识别模型通常是根据先验知识来构建,因此不能有效地应对目标数据中存在的噪音和不确定性。此外,随着识别模型复杂度的增加,推理的复杂度必然随着增加,导致识别效率下降。知识驱动的方法主要应用在单、多居民的日常行为识别,异构环境下的日常行为识别的场景下。数据驱动方法的优势在于能够较好地处理数据中存在的噪音以及不确定性,而且学习到的识别模型能够很好地覆盖日常行为的特征。其局限性在于识别模型的构建需要大量已标注的数据,此外,对数据的严重依赖导致学习到的模型的可移植性较差,模型的移植需要借助迁移学习完整源域到目标域的映射。基于数据驱动方法的优缺点,数据驱动的方法主要应用在单、多居民的日常行为识别,异构环境下的日常行为识别以及异常行为识别的场景下。
| 图表编号 | XD00201536900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.15 |
| 作者 | 刘勇、谢若莹、丰阳、王亚辉、刘亚清 |
| 绘制单位 | 四川轻化工大学人工智能四川省重点实验室、大连海事大学信息科学技术学院、大连海事大学信息科学技术学院、晋中职业技术学院电子信息学院、大连海事大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}