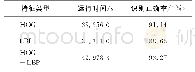
《表1 训练人数为20人时识别精度和时间比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
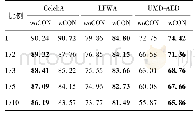
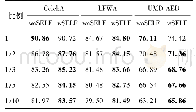
通过建立GMM说话人识别模型进行实验获得C-vector、MFCC和HDCC三种特征的训练精度、测试精度、建模时间和识别时间。尝试了不同数量的人(20、50、100、300、400、500和600人)。他们的演讲是TIMIT语音库的一部分,测试是两个演讲库,训练是八个演讲库。在这个实验中,本文进行了八次迭代来进行每个扬声器的训练和测试。得到的实验结果如表1~7所示。
| 图表编号 | XD00198045500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.31 |
| 作者 | 艾佳琪、左毅、刘君霞、贺培超、李铁山、陈俊龙 |
| 绘制单位 | 大连海事大学航海学院、大连海事大学航海学院、大连海事大学航海学院、大连海事大学航海学院、大连海事大学航海学院、大连海事大学航海学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}