《表1 CCKS CNER语料的数据统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于笔画ELMo和多任务学习的中文电子病历命名实体识别研究》
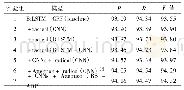
我们在CCKS17和CCKS18两个CNER评测数据集上进行实验,来验证本文方法在中文CNER任务上的有效性.这两个数据集都是电子病历文本数据,主要区别在于标注的实体有所不同.使用多个数据集也是为了验证本文方法具有较好的鲁棒性.(1)CCKS17.原始数据集分为训练集和测试集,其中训练集包括300个医疗记录,人工标注了五类实体(包括症状和体征、检查和检验、疾病和诊断、治疗、身体部位).测试集包含100个医疗记录;(2)CCKS18.同样原始数据集包括训练集和测试集.其中训练集包括600个医疗记录,人工标注了五类实体(包括解剖部位、症状描述、独立症状、药物、手术).测试集包含400个医疗记录.表1列出了数据集中不同类别的实体统计.由于我们基于多任务的方法涉及到两个任务的交互,需要关注的一个问题是,一个数据集的训练数据与另一数据集中的测试数据之间是否存在明显的重叠现象,因为这会使模型在评价多任务学习时不准确.经过对比统计,我们发现在医疗记录篇章级别,CCKS17和CCKS18并没有重叠数据;在句子级别,CCKS17测试集与CCKS18训练集重叠率为0.04%,CCKS18测试集与CCKS17训练集句子重叠率为0.15%.为了更准确的评价本文的方法,我们将这些少量的重叠数据从两个数据的训练集中直接去除.在实验中,我们分别随机选择20%的训练集数据作为各个数据集的开发集来调整超参数.此外,为了获得更高质量的预训练字和词向量,我们在知网上下载了医学类文摘,并将CCKS提供的中文电子病历文本进行合并,总计1 568 458篇文档作为无标注数据.为了公平比较,实验中所有字和词向量均使用该数据进行预训练.
| 图表编号 | XD00197663200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.01 |
| 作者 | 罗凌、杨志豪、宋雅文、李楠、林鸿飞 |
| 绘制单位 | 大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |

![表1 豆瓣对话语料的统计数据[4]](http://bookimg.mtoou.info/tubiao/gif/WHCH202102018_00600.gif)



{kind=link}